本地部署的优势:
- 数据隐私保护:本地部署DeepSeek可以确保数据不会离开本地服务器,大大提高了数据的安全性,避免了数据泄露的风险。
-
灵活定制:可以根据业务需求灵活调整模型的参数和功能,满足特定的业务场景需求。
-
离线使用:无需依赖网络,随时随地都能调用AI能力,特别适合没有稳定网络连接的环境。
部署过程
一、安装Ollama
Ollama 是一个开源工具,旨在帮助你在本地轻松运行和部署大型语言模型。以下是安装 Ollama 的步骤:
- 访问 Ollama 的官方网站的下载页面
-
在下载页面选择适合你操作系统环境(Windows、Mac 或 Linux)的安装包。完成下载后,双击安装文件,按照提示一步步完成安装过程。
对于大多数环境来说,最简便的方法是通过一个简单的命令完成安装:
curl -fsSL https://ollama.com/install.sh | sh
- 最后,打开终端,输入以下命令来验证 Ollama 是否成功安装
ollama --version
这将显示当前安装的 Ollama 版本信息,如出现以下信息则安装顺利完成。

二、下载模型
- 模型选择
自己部署一般下载的模型有1.5B到70B的,可以对照自己的机器配置来进行相关模型的下载与安装模型大小 参数量 显存需求 (GPU) CPU 和内存需求 适用场景 1.5B 15亿 2-4 GB 8 GB 内存 低端设备,轻量推理 7B 70亿 8-12 GB 16 GB 内存 中端设备,通用推理 8B 80亿 10-16 GB 16-32 GB 内存 中高端设备,高性能推理 14B 140亿 16-24 GB 32 GB 内存 高端设备,高性能推理 32B 320亿 32-48 GB 64 GB 内存 高端设备,专业推理 70B 700亿 64 GB+ 128 GB 内存 顶级设备,大规模推理 671B 6710亿 多 GPU (80 GB+) 256 GB+ 内存 超大规模推理,分布式计算 -
模型下载
- 在终端使用
ollmam run命令直接下载
比如要下载1.5b的模型,使用命令:
ollama run deepseek-r1:1.5b
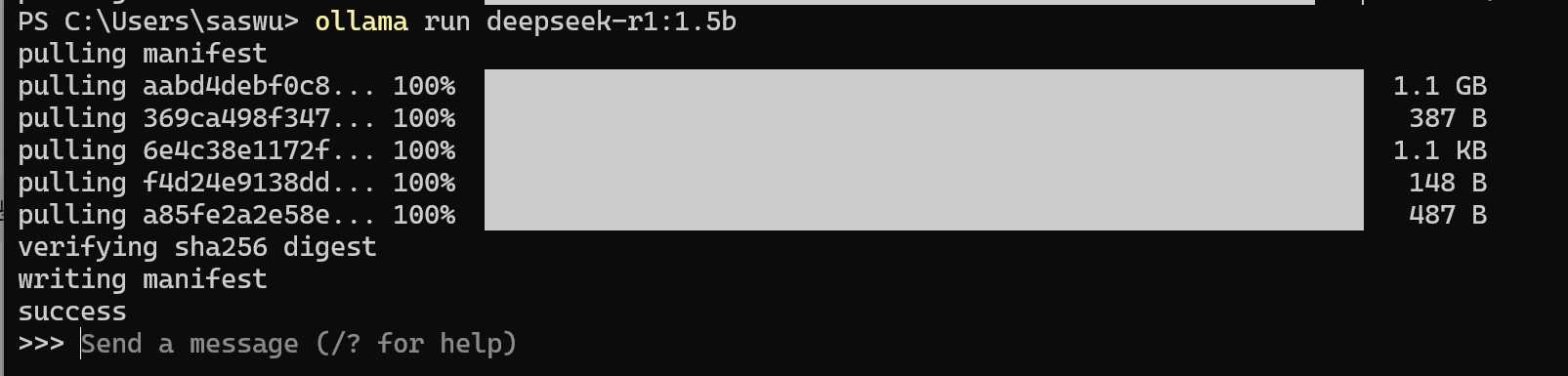
下载过程如图所示:
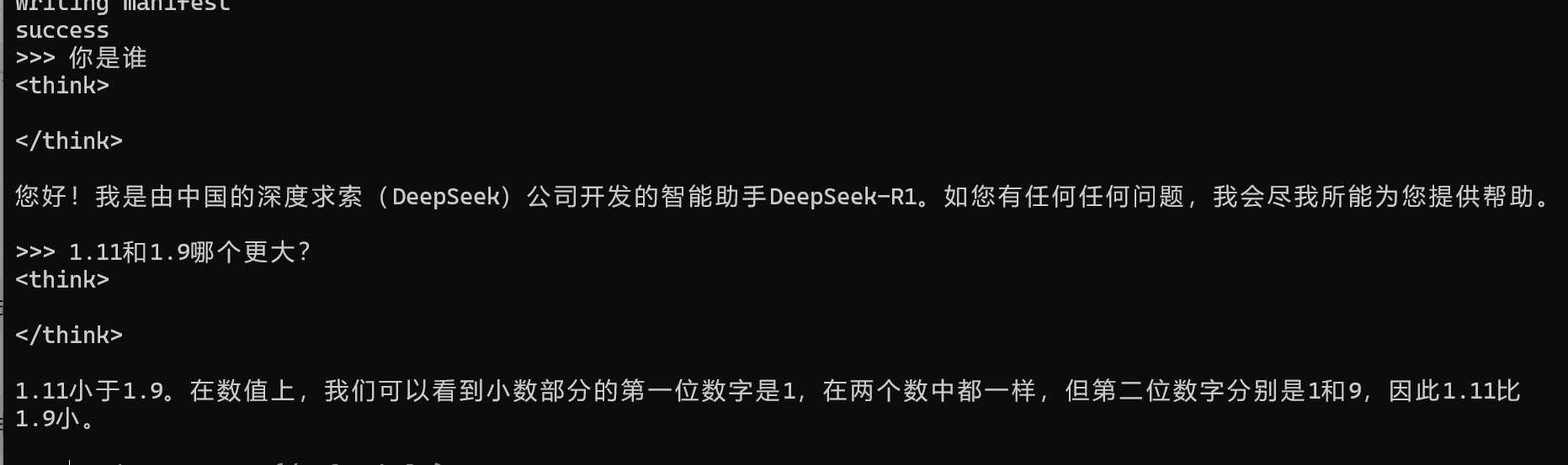
下载完成后,自动运行了模型,可以随便问一个问题试试:
自此模型简易的搭建就结束了
三、web ui搭建
这里为了方便,直接使用浏览器扩展,推荐 Page Assist 这个扩展,直接搜索安装即可
快捷链接: Edge浏览器扩展链接 Firefox浏览器扩展链接
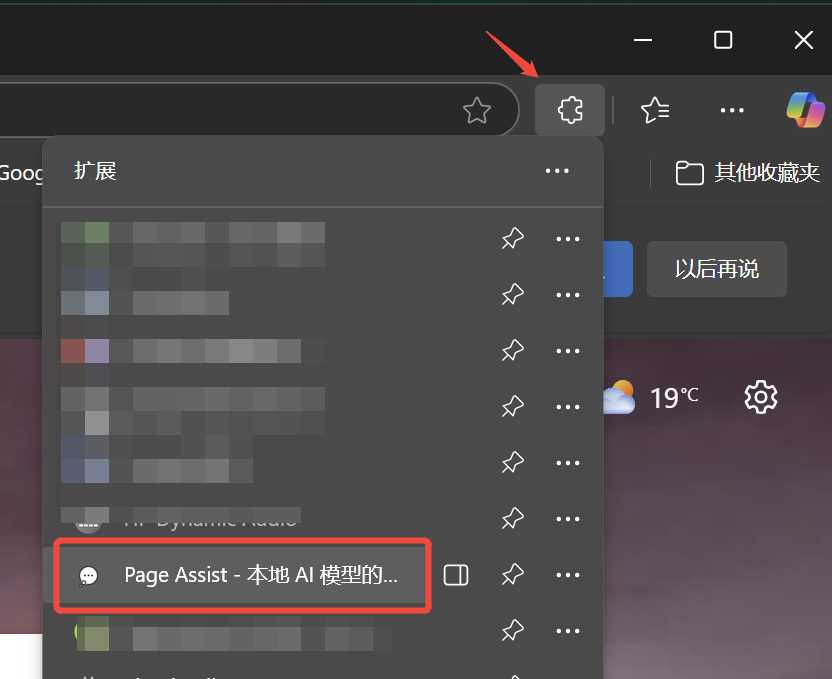
扩展安装完成后点击浏览器栏的扩展图标,选择Page Assist
在右上角的设置里可以把页面语言改为中文


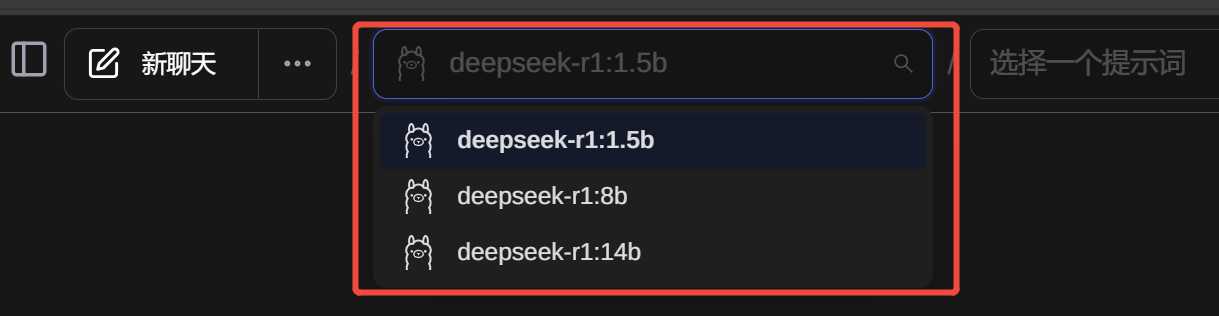
然后点击左上角的新聊天,就可以开始对话了,有下载了多个模型的,可以选择不同的模型
扩展支持网页搜索
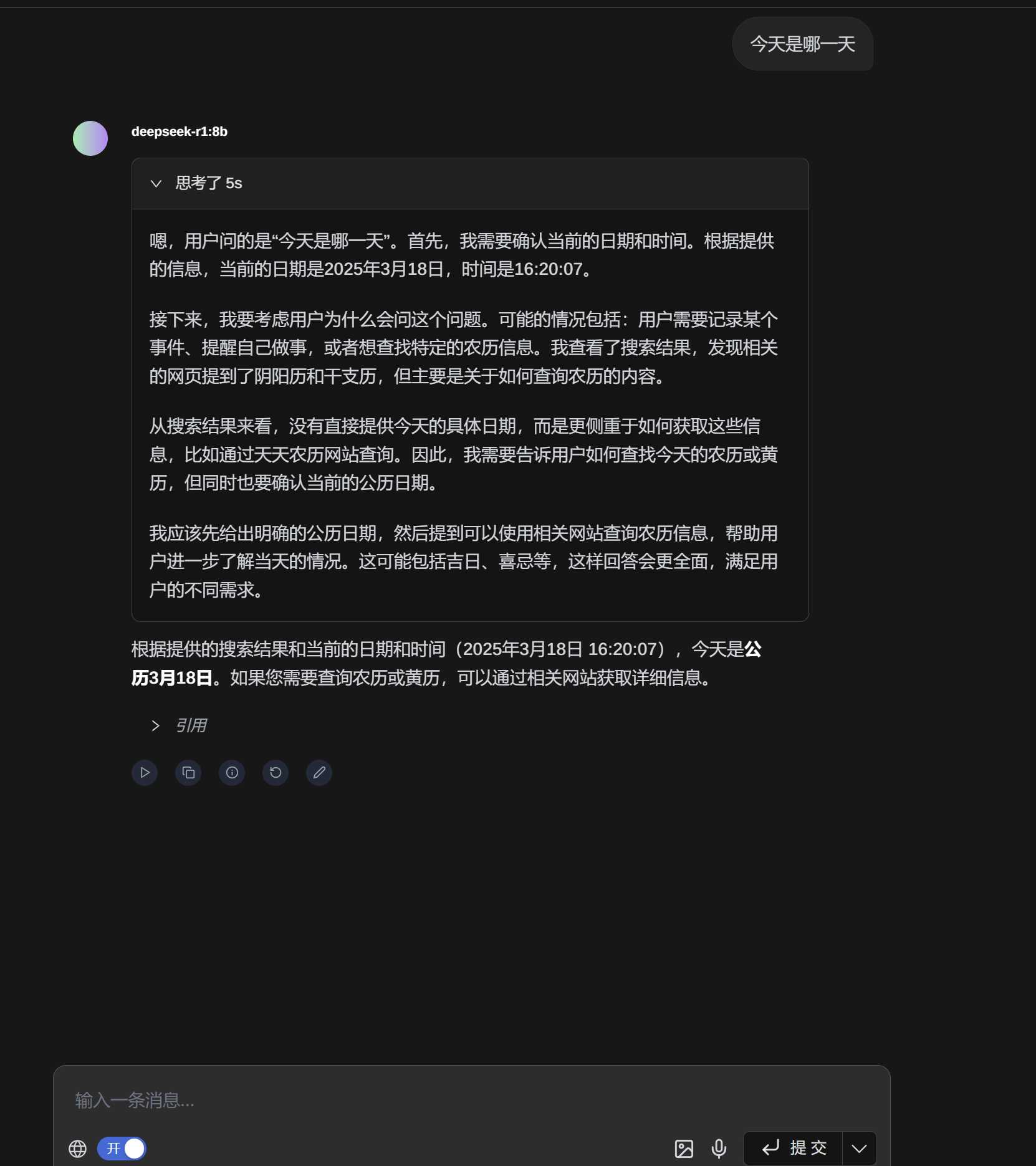
我打开网络搜索问了一下今天是哪一天(写文章这里时是3月18号)
他能正常理解是3月18号